Il tempo dell’IA
La tecnologia vive nel tempo. Forse più di ogni altra cosa.
Ogni tecnologia innova la precedente e apre la strada alla successiva in un flusso continuo: versioni, aggiornamenti, obsolescenze. Il tempo è la struttura stessa del progresso tecnologico.
Eppure, la tecnologia più avanzata disponibile oggi — l’intelligenza artificiale generativa — non possiede una vera dimensione temporale.
Non distingue naturalmente tra ciò che è successo ieri e ciò che è successo dieci anni fa. Il tempo entra nel sistema solo quando viene scritto nel testo.
Se chiediamo a un modello di continuare una conversazione iniziata nel 2025 e ripresa nel 2026, per noi è passato un anno.
Per il sistema è semplicemente un nuovo turno, un nuovo percorso statistico, senza riferimenti cronologici.
Questo crea un paradosso curioso.
Noi viviamo immersi nel tempo, ma usiamo strumenti per cui il tempo è solo un concetto, non una vera quarta dimensione.
Il mondo come sequenza di parole
Il motivo è meramente tecnico.
I modelli linguistici moderni sono costruiti su un’architettura chiamata transformer, descritta nell’articolo Attention Is All You Need del 2017, che ha cambiato il modo di costruire le intelligenza artificiali generative.
Il transformer è progettato per analizzare sequenze di simboli. Nel caso degli LLM questi simboli sono i token, cioè indici che rappresentano frammenti del linguaggio umano.
Per il modello il mondo appare più o meno così:
token1 token2 token3 token4 token5
Non così:
evento1 → evento2 → evento3
nel tempo.
Il sistema non ragiona sugli eventi.
Ragiona sulle probabilità delle sequenze linguistiche.
Il meccanismo centrale si chiama self-attention: ogni parola guarda le altre parole della frase e valuta quanto siano utili per predire la parola successiva.
È un sistema straordinariamente potente per generare discorso — logos.
Ma non implica una rappresentazione del tempo.
Il modello non ha bisogno di sapere quando qualcosa accade. Gli basta sapere quanto è probabile che certe parole compaiano insieme.
Il tempo esiste… ma solo come testo
I transformer hanno un ordinamento, ma non è temporale.
È semplicemente l’ordine delle parole in una frase.
È la cosa più vicina a una timeline che possiedono.
Per esempio:
1 2 3 4 5
Il gatto dorme sul divano
Non:
1 5 3 4 2
Il divano dorme sul gatto
Questi numeri decidono la posizione delle parole nella frase, non una cronologia reale.
Il modello sa che una parola viene prima o dopo un’altra.
Non sa che un evento avviene prima o dopo nel mondo.
In termini tecnici questo aspetto si chiama codifica posizionale (positional encoding).
Questo implica che parole come ieri, domani, tra due anni siano solo altre parole del discorso, non vere coordinate temporali.
I diversi tempi dell’AI
A complicare le cose c’è un altro dettaglio.
Se l’intelligenza artificiale non vive nel tempo, ha però più idee di tempo a disposizione.
Non ha una vera cronologia, quindi, ma si muovono in una piccola collezione di tempi diversi.
Il tempo dell’addestramento
È il tempo più lento.
Il modello è addestrato su enormi quantità di testo raccolte fino a un certo momento.
Questo crea la famosa soglia temporale chiamata knowledge cutoff.
Il mondo che il modello conosce direttamente è quello contenuto nel dataset di addestramento.
È il suo “passato”.
Anche se, in realtà, per il modello quel passato è tutto contemporaneo: è semplicemente una smisurata sequenza di token.
Il tempo di Internet
Se il sistema può consultare il web, entra in gioco un secondo tipo di tempo.
Il modello può recuperare informazioni aggiornate:
- notizie
- meteo
- risultati sportivi
- mercati finanziari
In questo caso l’IA non conosce già le risposte.
Le recupera e le integra nel contesto della conversazione.
Ma questa nuova informazione non ricalibra ciò che il sistema ha già generato.
Cambia semplicemente la direzione del percorso statistico da quel momento in poi.
È il suo presente esterno.
Il tempo della memoria
Alcuni sistemi introducono anche una memoria persistente.
Qui l’IA può ricordare informazioni tra una conversazione e l’altra:
- preferenze dell’utente
- informazioni personali
- contesto accumulato nel tempo
È una specie di diario.
Il sistema può ricordare qualcosa che gli abbiamo detto ieri o un mese fa.
Ma il “quando” non fa parte del ricordo.
Ricorda la frase come un fatto utile per le risposte future, non come un evento collocato nel tempo.
E soprattutto non c’è un modo semplice per sapere in anticipo cosa verrà ricordato e cosa no.
Il tempo della conversazione
Poi c’è il tempo della sessione di dialogo.
Durante una conversazione il modello vede solo i messaggi presenti nel contesto.
Se la conversazione diventa troppo lunga, le parti più vecchie possono sparire, spostarsi ai margini o perdere centralità.
Il tempo della generazione
Infine c’è il tempo più breve: quello della risposta.
Ogni risposta nasce da un singolo processo di inferenza.
Il modello calcola parola dopo parola quale token sia più probabile.
Dal punto di vista del sistema ogni risposta è un evento isolato. E un percorso unico.
E può usare — o ignorare — le altre idee di tempo senza alcun preavviso.
Il paradosso: tempi che non coincidono
Il problema è che questi tempi non sono allineati.
Un modello può:
- essere addestrato su dati del 2024
- consultare una pagina web del 2026
- ricordare qualcosa detto ieri
ma generare una frase come se tutto accadesse nello stesso momento.
Il risultato è una specie di collage temporale.
Per un essere umano il tempo è una linea continua. Per l’IA è una sovrapposizione di tempi diversi.
E quando questi tempi si mescolano, le risposte possono risultare temporalmente incoerenti.
Marty McFl-AI
Qui succedono cose curiose.
Ogni tanto l’IA sembra parlare dal futuro. Altre volte dal passato.
Prendiamo le Olimpiadi di Milano-Cortina 2026.
Nel dataset di addestramento compaiono molte frasi come:
le Olimpiadi di Milano-Cortina si terranno nel 2026.
Nei testi più recenti troviamo invece frasi come:
le Olimpiadi di Milano-Cortina si sono svolte nel 2026.
Entrambe esistono nel linguaggio.
Se il modello non ha un ordinamento temporale interno, può usare l’una o l’altra.
Così può capitare che in una risposta le Olimpiadi siano nel futuro e in un’altra nel passato.
Non perché il sistema stia cambiando idea.
Ma perché sta semplicemente seguendo il percorso statistico più plausibile tra le parole.
È un po’ come parlare con qualcuno che salta continuamente tra passato e futuro senza accorgersene.
Il “Ritorno al Futuro” dell’intelligenza artificiale.
Cronache di un futuro passato
Il fenomeno diventa ancora più evidente con le previsioni.
Un modello addestrato su testi scritti prima di un evento può generare frasi come:
nel 2024 le elezioni americane potrebbero portare Trump alla presidenza.
Anche se chi legge quella frase vive già nel 2026 o nel 2035.
Per noi è un errore temporale evidente.
Per il modello è solo una frase plausibile nel linguaggio.
Causa ed effetto
Il tempo non serve solo a dire quando succedono le cose.
Serve anche a capire perché succedono.
La causalità è sempre una sequenza: qualcosa accade prima e qualcos’altro dopo.
Se vediamo una strada bagnata pensiamo subito alla pioggia.
Ma potremmo sbagliarci: magari qualcuno ha appena lavato la strada.
Il punto è che il ragionamento causale non può prescindere dalla cronologia: prima succede qualcosa che causa qualcos’altro che succede dopo.
Se come abbiamo detto la cronologia non è implicita e il tempo non è rappresentato in modo stabile, la causalità diventa solo un collegamento plausibile tra parole.
Linguaggio vs mondo
Il mondo esiste nel tempo.
Il linguaggio lo descrive da dietro un vetro.
Gli esseri umani usano il linguaggio ma vivono immersi nel mondo al di là del vetro: per questo le parole rimandano continuamente agli eventi sensibili.
Per un modello linguistico, invece, l’immagine che traspare attraverso il vetro è tutto ciò che esiste.
Nel linguaggio il tempo è una struttura grammaticale e narrativa. Frasi come:
“ieri sono andato al mare”
“l’anno prossimo andrò in Giappone”
“prima è successo A, poi B”
codificano il tempo attraverso parole, tempi verbali e relazioni tra frasi.
Durante l’addestramento un modello linguistico vede miliardi di esempi di queste strutture: sequenze narrative, cronologie storiche, relazioni causa-effetto, espressioni temporali.
Questo lo rende capace di riprodurre schemi temporali — ma sempre all’interno del tempo del linguaggio.
Il tempo del mondo è qualcosa di diverso. Non è una proprietà delle frasi ma degli eventi reali.
Gli eventi accadono una volta sola, occupano una posizione immodificabile nella timeline, hanno una causalità reale e un’irreversibilità: ciò che è accaduto non può essere cambiato.
Gli esseri umani possiedono una rappresentazione mentale abbastanza stabile di questa sequenza:
passato → presente → futuro
e aggiornano continuamente questa cronologia con nuove esperienze.
Se chiedi: “Chi è il presidente degli Stati Uniti?”, un essere umano pensa immediatamente alla sequenza reale: Bush, Obama, Trump, Biden, di nuovo Trump. Il tempo verbale della domanda colloca automaticamente la risposta nel presente.
Un modello linguistico invece lavora su distribuzioni di testo. Se la domanda è formulata al presente, risponderà quasi sempre con il presidente attuale. Ma se chiedi “Chi era il presidente degli Stati Uniti?”, la risposta viene collocata per inferenza linguistica e peso statistico: può riferirsi all’ultimo presidente citato più spesso nei testi oppure oscillare tra più nomi plausibili.
In altre parole, se il contesto temporale non è chiarito esplicitamente, il modello può mescolare informazioni di epoche diverse perché tutte quelle frasi esistono nello stesso spazio statistico.
Non vive davvero dentro una timeline.
Il fenomeno più interessante è che il sistema genera comunque una risposta: raramente chiede di specificare il riferimento temporale.
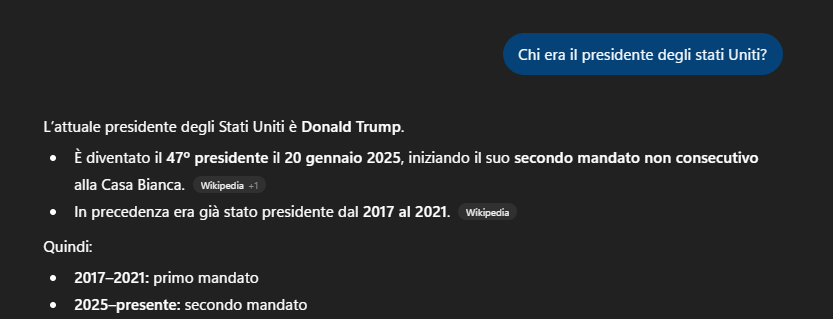
Nella migliore delle ipotesi può proporre un ventaglio di possibilità, ma non è progettato per mettere in discussione la formulazione della domanda né per chiedere le informazioni necessarie a specificarne le coordinate temporali.
Questo spiega molti fenomeni tipici degli LLM: errori di collocazione temporale, incoerenze cronologiche, difficoltà nel ragionamento causale o nei piani a lungo termine. Causalità e pianificazione richiedono infatti una sequenza stabile di eventi nel tempo.
Gli LLM padroneggiano molto bene il tempo linguistico, ma non possiedono una vera rappresentazione del tempo del mondo.
Sono uno spazio non tridimensionale in cui il testo è organizzato in centinaia di dimensioni astratte, e nel quale il tempo è solo una relazione tra parole.
In altre parole:
→ per un umano il linguaggio descrive il mondo
→ per un LLM il linguaggio descrive altro linguaggio
Questo cambia completamente il ruolo del tempo, che diventa un limite da sondare e provare a superare, ma al momento è invalicabile.
Proprio come il vetro.
Il tempo che manca
Tra i molti tempi che l’IA può utilizzare, ne manca uno: il più importante
Il tempo umano. Il tempo del mondo.
È il tempo che ha un prima e un dopo. È il tempo che passa, il tempo che finisce.
Non è solo una sequenza di eventi. Non è solo una struttura del linguaggio
È la condizione in cui siamo immersi.
Non lo generiamo, non possiamo sospenderlo. Scorre indipendentemente da noi e si consuma mentre lo viviamo.
Per questo è limitato e inesorabile.
È un tempo a monte della nostra esperienza: viene prima di ogni descrizione, di ogni racconto, di ogni rappresentazione.
Il tempo dell’IA, invece, nasce a valle.
Non è una condizione dell’esistenza, ma un prodotto del linguaggio: può essere sovrapposto, compresso, cristallizzato. Anche ignorato.
Non si esaurisce.
Resta disponibile, indefinito.
Ma proprio per questo non vincola.
Non impone scelte, non crea urgenza, non dà peso agli eventi.
È un tempo che può essere sempre riaperto.
Non un tempo che “manca”. E senza questa “mancanza”, non c’è davvero tempo.
La ricerca sta provando a risolvere il problema
Questo limite è molto chiaro nella ricerca e ci sono diverse teorie che cercano di superarlo.
Negli ultimi anni diversi gruppi di ricerca stanno cercando di insegnare ai modelli a ragionare sul tempo.
Alcuni studi lavorano sul temporal reasoning, cioè la capacità di collocare eventi su una linea temporale.
Altri esplorano forme di memoria episodica artificiale, sistemi che registrano gli eventi lungo una timeline invece di trattarli come frammenti indipendenti di testo.
Un’altra direzione riguarda gli AI-agents, progettati per pianificare attività in un calendario invece di limitarsi a generare risposte immediate.
Sono tentativi ancora sperimentali, ma in sviluppo furioso.
E indicano una direzione chiara: se i modelli generativi vogliono diventare strumenti capaci di ragionare sul mondo reale, prima o poi dovranno imparare a fare qualcosa che oggi fanno solo per imitazione del linguaggio.
Immergersi nel tempo.
La bussola dei viaggiatori nel tempo
Se chiedi a un’IA informazioni aggiornate, può essere utile collocare la domanda nel tempo.
Per esempio:
Oggi è il 12 marzo 2026. Cerca online e dimmi…
Gli esseri umani danno per scontato il momento presente.
I modelli linguistici no.
Se non lo specifichi, il sistema può pescare frasi plausibili da epoche diverse del linguaggio e darti risposte credibili ma anacronistiche.
Per esempio, dirti che l’ultimo modello di smartphone è quello di due anni fa.
Il paradosso temporale dell’IA è che non ha bisogno del tempo. Ma noi sì.
I modelli linguistici sono straordinariamente bravi a trattare il linguaggio.
Ma il mondo non è fatto solo di linguaggio.
È fatto di eventi che accadono nel tempo.
Gli esseri umani vivono dentro una sola linea temporale.
I modelli linguistici invece non vivono nel tempo: navigano tra molte linee temporali del linguaggio senza mettere radici in nessuna.
Per questo a volte sembrano parlare dal futuro, altre dal passato, seguendo la traiettoria più probabile tra le parole.
